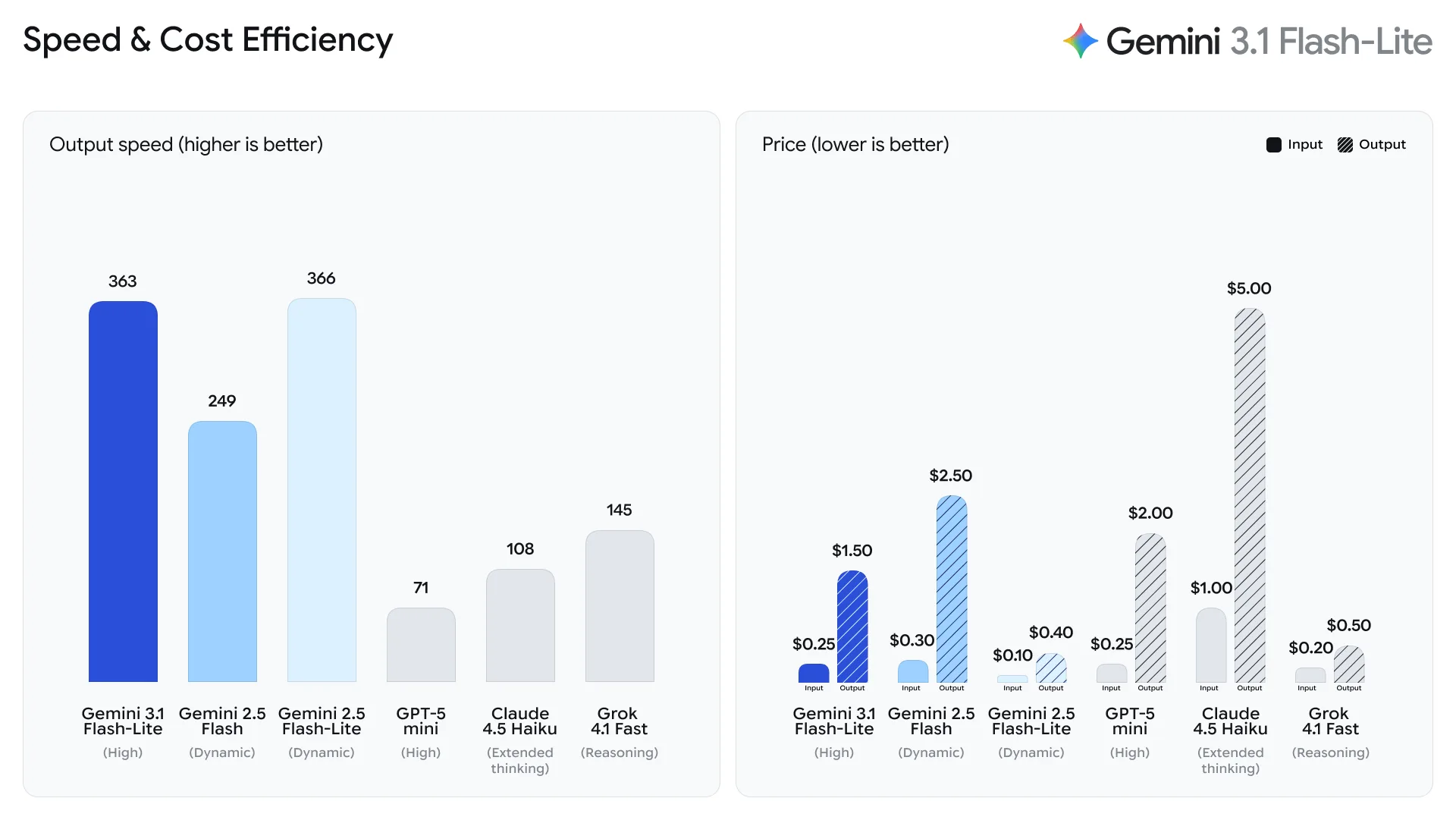
LLMの量子化
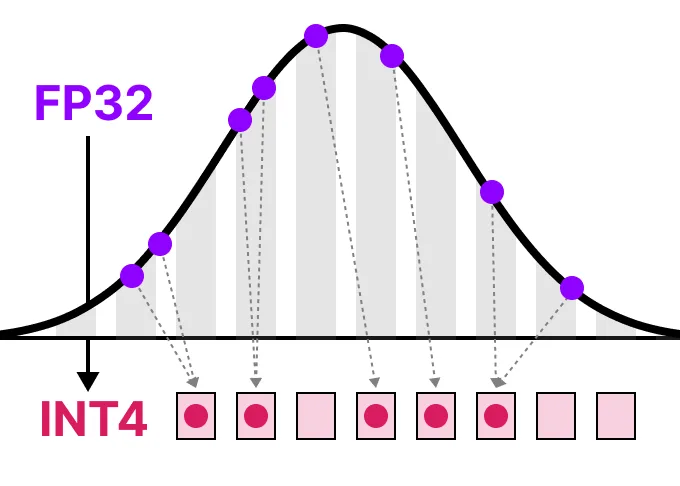

LLMモデルのパラメータの精度を、より高い32bit浮動小数点などから、より低い8bit整数などに下げることで小型化すること
- LLMは多くの場合は数十億のパラメータを超え、高速な推論のためには大規模なVRAMを備えたGPUが必要
- そのため、トレーニングやアダプターの改良によりモデルを小型化する研究が増えている
- この領域の主要技術の一つが量子化 Quantization である
特定の値に格納できるメモリ量の概算
-
- 64-bits = 64/8 × 70B → 560GB
- 32-bits = 32/8 × 70B → 280GB
- 16-bits = 16/8 × 70B → 140GB
- FP16精度すら70Bモデルのロードに140GBメモリが必要
ref: